故障恢复
故障恢复
- 故障可能会破坏数据库的一致性
- 破坏事务的持久性
- 已提交的事务对数据库的修改未全部持久化到磁盘
- 破坏事务的原子性
- 已中止的事务对数据库的修改已部分持久化到磁盘
分类
- 事务故障
- 逻辑错误:事务由于内部错误而无法完成,如违反完整性约束
- 内部状态错误:DBMS由于内部状态错误(如死锁)而必须中止活跃事务
- 系统故障
- 软件故障:DBMS实现的bug所导致的故障
- 硬件故障:运行DBMS的计算机发生崩溃(如断电)
- 存储介质故障
- 非易失存储器发生故障,损坏了存储的数据
- 假设数据损坏可以被检测,如使用校验和
- 任何DBMS都无法从这种故障中恢复,必须从备份中还原
1. Buffer Pool Policies
- Undo(撤销)
- 撤销未完成事务对数据库的修改
- Redo(重做)
- 重做已提交事务对数据库的修改
STEAL/NO-STEAL策略
- DBMS是否允许将未提交事务所做的修改写到磁盘并覆盖现有的数据?
- STEAL:允许
- NO-STEAL:不允许
FORCE/NO-FORCE策略
- DBMS是否强制事务在提交前必须将其所做的修改写到磁盘?
- FORCE:强制
- NO-FORCE:不强制
NO-STEAL + FORCE
- NO-STEAL:未提交事务不可能将其修改写回磁盘(无需undo)
- FORCE:已提交事务已将其修改全部写回磁盘(无需redo)
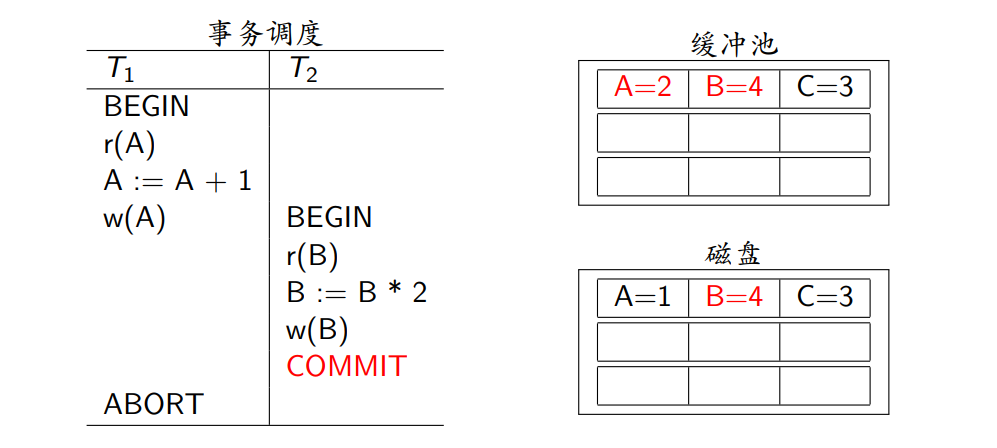
- 优点:实现简单
- 缺点:缓冲池得能存得下所有未提交事务所做的修改
2. Write-Ahead Logging(WAL)
预写式日志
- DBMS在数据文件之外维护一个日志文件(log file),用于记录事务对数据库的修改
- 假定日志文件存储在稳定存储器中
- 日志记录(log record)包含undo或redo时所需的信息
- DBMS在将修改过的对象写到磁盘之前,必须先将修改此对象的日志记录刷写道磁盘
WAL协议
- 当事务$T_i$启动时,向日志中写入记录<tid, BEGIN>
- tid:$T_i$的ID
- 当$T_i$提交时,向日志中写入记录<tid, COMMIT>
- 在DBMS向应用程序返回确认消息之前,必须保证$T_i$的所有日志记录都已刷写到磁盘
- <tid, COMMIT>写入磁盘才代表事务提交
- 当$T_i$修改对象A时,向日志中写入记录<tid, oid, before, after>
- oid:A的ID
- before:A修改前的值
- after:A修改后的值
事务的分类
- 已提交事务(committed txn)
- 既有<T, BEGIN>,又有<T, COMMIT>
- 不完整事务(imcomplete txn)
- 只有<T, BEGIN>,而没有<T, COMMIT>
- 已中止事务(aborted txn)
- 既有<T, BEGIN>,又有<T, ABORT>
- 在事务正常执行和故障恢复过程中,如果T所做的修改已全部撤销,则将日志记录<T, ABORT>写到日志
- 已中止事务相当于从未执行过,故不需要undo,更不需要redo
基于WAL的故障恢复
- 事务正常执行时的行为
- 记录日志
- 按照缓冲池策略将修改过的对象写到磁盘
- 故障恢复时的行为
- 根据日志和缓冲池策略,对事物进行undo或redo
- 已提交事务
- 如果一个已提交事务的修改已全部写到磁盘,则无需redo
- 否则,需要redo
- 不完整事务
- 如果一个不完整事务的任何修改都未写到磁盘,则无需undo
- 否则,需要undo
WAL协议实现
根据缓冲池策略的不同进行分类
(1). Undo Logging
WAL+STEAL+FORCE 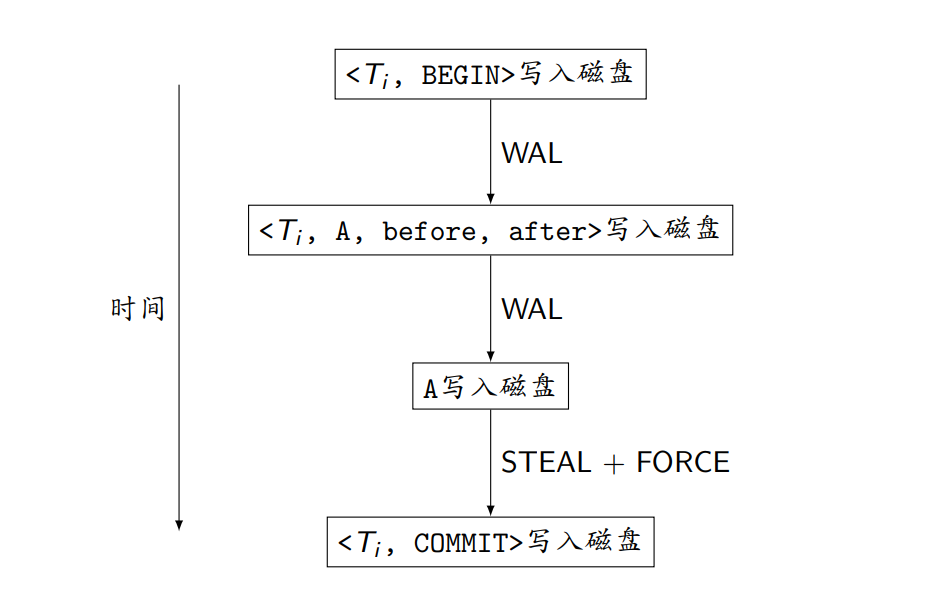
- 故障恢复方法:从后向前扫描日志
- <T, COMMIT>:将T记录为已提交事务(无需redo)
- <T, ABORT>:将T记录为已中止事务(无需undo)
- <T, A, before, after>:如果T是不完整事务,则将磁盘上A的值恢复为before
- <T, BEGIN>:T恢复完毕;如果T是不完整事务,则向日志中写入<T, ABORT>(今后故障恢复时无需再undo)
(2). Redo Logging
WAL+NO-STEAL+NO-FORCE 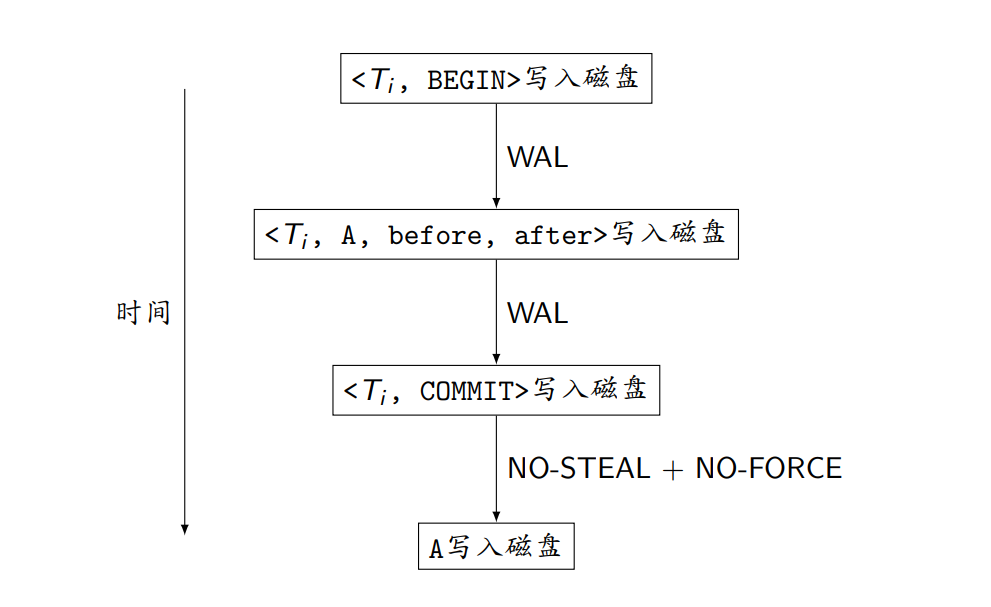
- 故障恢复方法:从前向后扫描日志2遍
- 第1遍扫描:记录已提交事务和已中止事务
- <T, COMMIT>:将T记录为已提交事务(需要redo)
- <T, ABORT>:将T记录为已中止事务(无需undo)
- 第2遍扫描:根据每条日志记录的类型执行相应的动作
- <T, A, before, after>:如果T是已提交事务,则将磁盘上A的值覆写为after
- <T, BEGIN>:如果T是不完整事务,则向日志中写入<T, ABORT>
- 第1遍扫描:记录已提交事务和已中止事务
(3). Redo+Undo Logging
WAL+STEAL+NO-FORCE 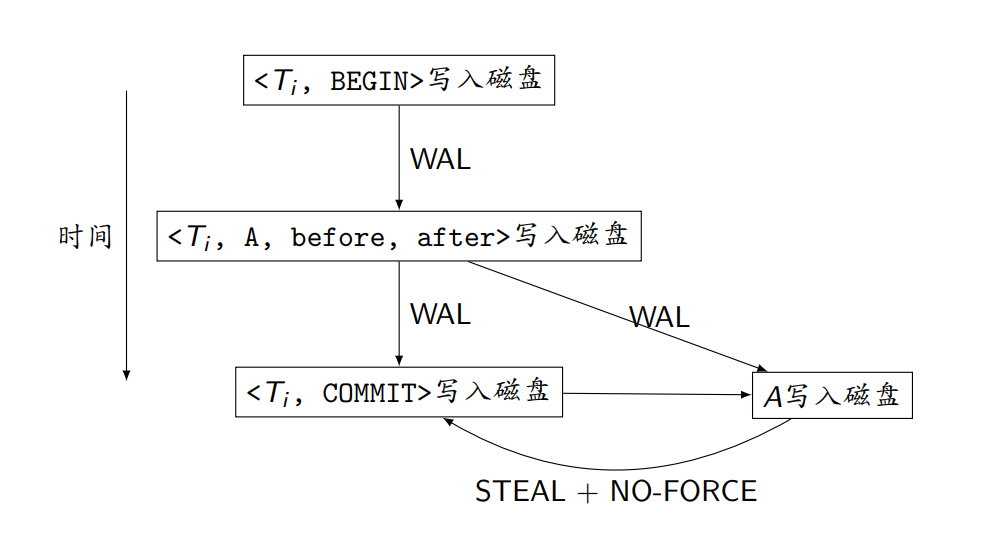
- 故障恢复时既要redo又要undo
- 运行时效率最高,故障恢复时效率最低
几乎所有DBMS都采用STEAL+NO-FORCE
组提交
内存中设置日志缓冲区,将日志记录写到日志缓冲区,然后成批刷写到日志文件
- 日志缓冲区满时刷写
- 定时刷写
3. Checkpoints
- WAL的问题
- 日志永远在变大
- 故障恢复时需要扫描日志,恢复时间越来越长
模糊检查点
- 检查点开始:向日志中写入<BEGIN CHECKPOINT (T1, T2, …, Tn)>
- T1,T2,…,Tn是检查点开始时的活跃事务
- 活跃事务是尚未提交或中止的事务
- 检查点中间:根据缓冲池策略,将脏页写到磁盘
- 如果采用STEAL,则将全部脏页写到磁盘
- 否则,只将已提交事务所做的修改写到磁盘
- 检查点结束:向日志中写入<END CHECKPOINT>,并将日志刷写到磁盘
- 如果采用NO-FORCE,则写完全部脏页后即可结束检查点
- 否则,在T1,T2,…,Tn全部提交后,才能结束检查点
对于STEAL+NO-FORCE策略的故障恢复
- Redo阶段
- 需要redo的最早的事务一定属于{T1, T2, …, Tn}
- Undo阶段
- 需要undo的最早的事务一定属于{T1, T2, …, Tn}
- 扫描到其中最早的事务Ti的日志记录<Ti, BEGIN>为止
This post is licensed under CC BY 4.0 by the author.